Found a problem, the page exists and visually normal display, but the search robot can not read (scan) it. Strange, but it happens.
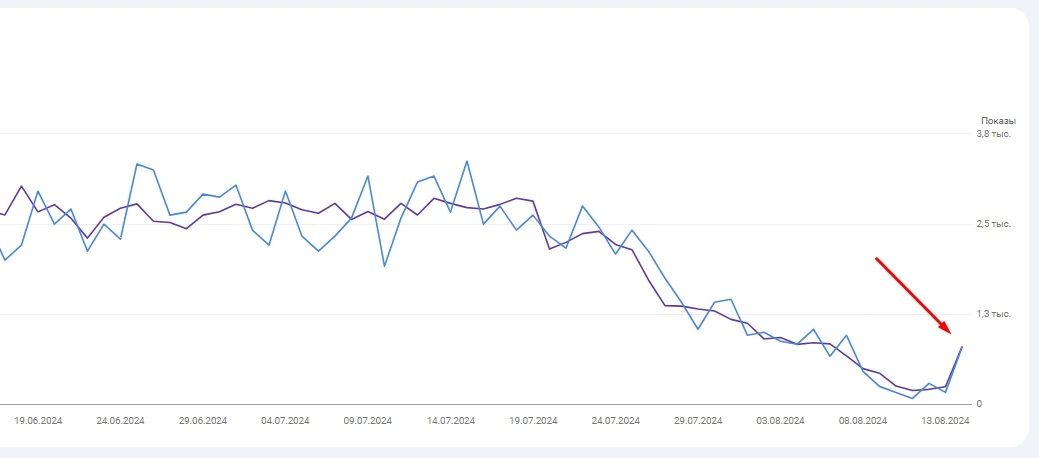
During the initial audit of the site using Screaming Frog and Serpstat, the problem was not detected, but the search console before your eyes shows a significant drop in traffic, while excluding the option of imposing sanctions or filters.
Since the problem was first detected in Search Console, we start from it. We select any page excluded from the index and the page that is still in it and check them with the “cache:” operator. It turns out that both pages have a 404 response from webcache.googleusercontent.com.
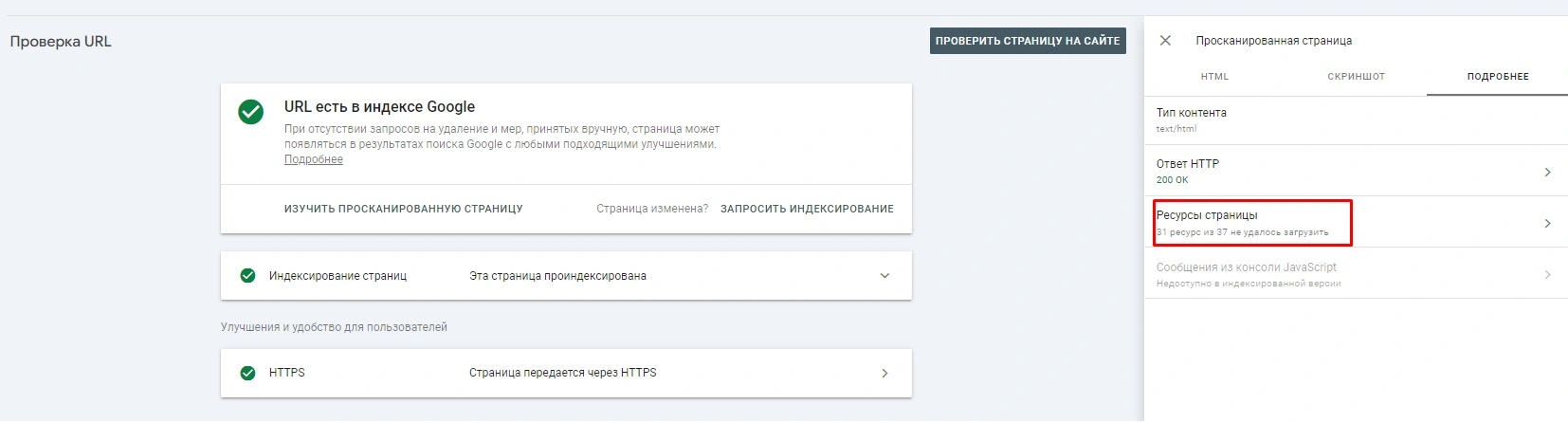
Go back to the console and check these two URLs, then examine the scanned page.
As it turned out, the problem was hidden in the resources of the page, out of 50 units loaded only 2 (on the screen the problem is mostly already fixed).
What is the reason for this, it is already an individual question. We need to understand why the search engine can not load the remaining 48 resources, because it is because of this that the pages of the site rapidly began to fall out of the index.
This is why it is so important to monitor how the search robot scans and sees the site.