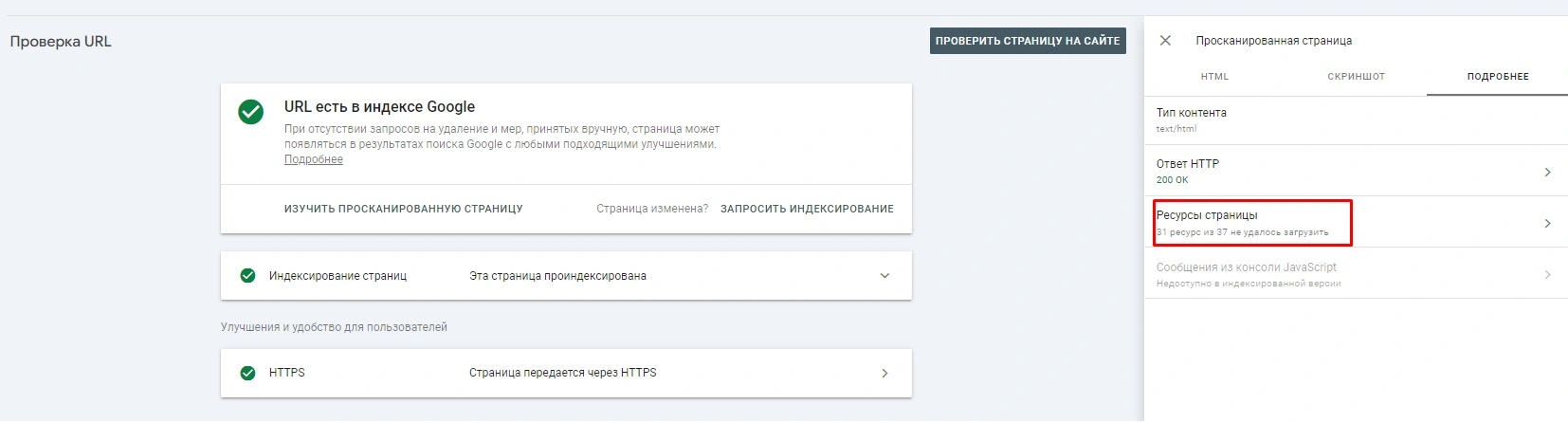
Es wurde ein Problem entdeckt: Die Seite existiert und wird visuell normal angezeigt, aber der Suchroboter kann sie nicht lesen (scannen). Überraschenderweise passiert das.
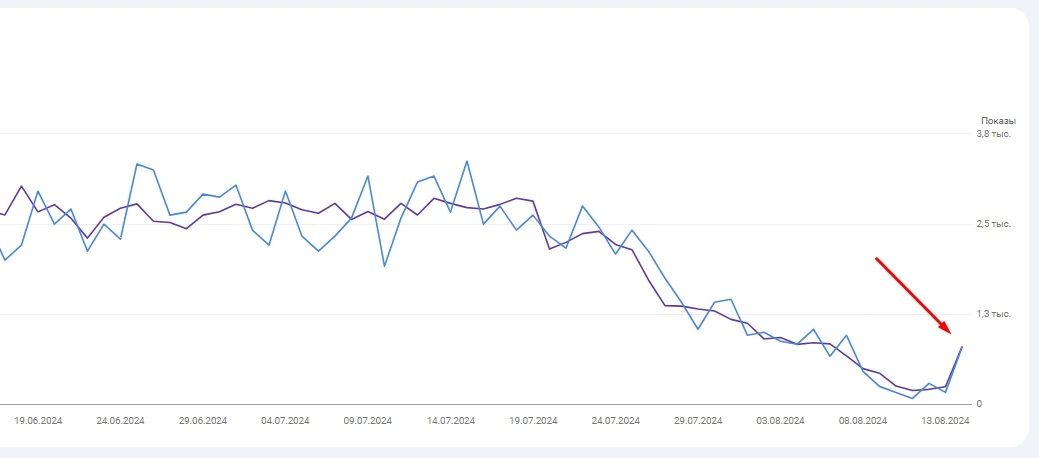
Bei der anfänglichen Prüfung der Website mit Screaming Frog und Serpstat wurde das Problem nicht entdeckt, aber die Search Console zeigt einen deutlichen Rückgang des Traffics, während die Möglichkeit, Sanktionen oder Filter zu verhängen, ausgeschlossen ist.
Da das Problem zuerst in der Search Console entdeckt wurde, beginnen wir dort. Wir wählen eine beliebige Seite, die aus dem Index ausgeschlossen wurde, und eine Seite, die noch im Index vorhanden ist, und überprüfen sie mit dem Operator „cache:“. Es stellt sich heraus, dass beide Seiten eine 404-Antwort von webcache.googleusercontent.com haben.
Wir kehren zur Konsole zurück und überprüfen diese beiden URLs und dann die gecrawlte Seite.
Wie sich herausstellte, war das Problem in den Seitenressourcen versteckt, nur 2 von 50 Einheiten wurden geladen (das Problem wurde im Screenshot größtenteils behoben).
Der Grund dafür ist eine individuelle Frage. Man muss verstehen, warum die Suchmaschine die verbleibenden 48 Ressourcen nicht laden kann, denn das ist der Grund, warum die Seiten der Website schnell aus dem Index zu fallen begannen.
Deshalb ist es so wichtig, zu beobachten, wie der Crawler der Suchmaschine Ihre Website durchsucht und sieht.